Managing dotfiles with a bare git repo
I use dotfiles to configure my environment.
I had the dotfiles stored in a git repo and used helper scripts to create symlinks in my $HOME directory. However, adding & updating the dotfiles felt cumbersome, like a pebble in a shoe.
Recently, I stumbled upon this article, which was inspired by this HN comment. They mention something called a bare git repo to manage dotfiles. I have never heard of it & it took me a while to figure it out. So I thought I will share it here.
How a typical git repo looks like #
Typically, when you initialize or clone a git repo, it consists of two parts: the working tree and the .git directory. The working tree contains things like source code and the README. The .git directory contains git internals, such as commit objects, local git config, and hooks. For example, when you checkout a different branch, git updates the working tree based on data stored in the .git directory.
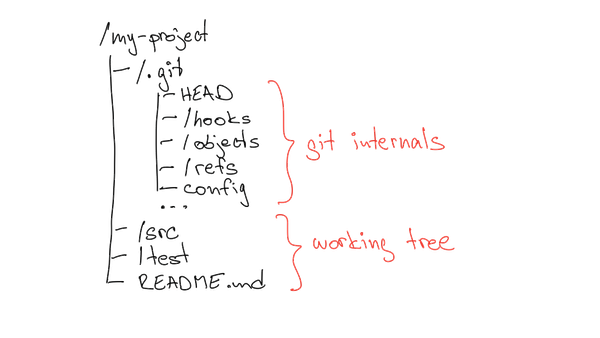
Cumbersome symlinking #
Now, when symlinking dotfiles, the working tree for dotfiles is located in the dotfiles git directory, not in $HOME. So to make dotfiles work, one needs to create symlinks. And the symlinks need to be managed. That's the pebble.
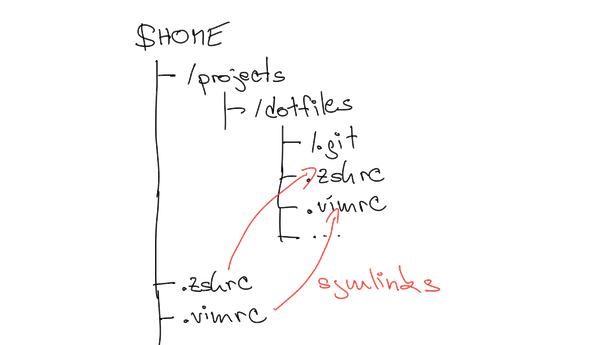
You may wonder why not initialize a git repo directly in $HOME? If git doesn't find the .git directory in the current directory, it continues the search in parent directories. So if a directory is not versioned, git would still assume we are in the dotfile git repo. That could be confusing & prone to errors.
If only there would be a way to put the dotfiles working tree directly in $HOME, while keeping the .git directory separated.
Say hello to bare repositories #
It turns out there is a way: a bare git repository. A bare git repo is a repo that contains only the content of the .git directory, not the working tree. When interacting with git, you specify the working tree directory as a command-line parameter. That's pretty nice.
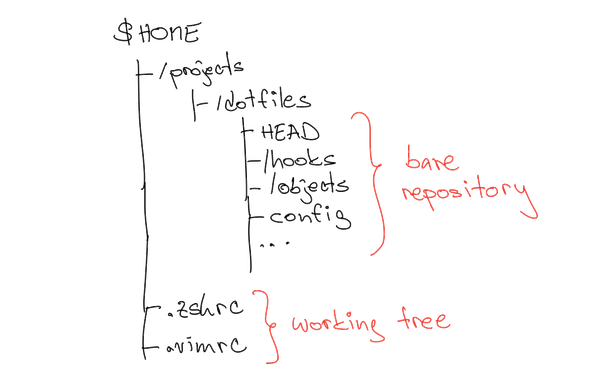
Technically, it's done like this.
$ DOTFILES=$HOME/projects/dotfiles.git
# init the repository with the --bare flag
$ git init --bare $DOTFILES
# setup a git alias which sets
# the .git directory to $DOTFILES and
# the working tree to $HOME
$ alias gitdf='git --git-dir=$DOTFILES --work-tree=$HOME'
# for gitdf status don't show untracked files
$ gitdf config status.showUntrackedFiles no
# making a change & commiting a dotfile
$ echo "syntax on" >> .vimrc
$ gitdf add .vimrc
$ gitdf commitI've been using this setup for a few days now, and it feels smoother. I like it.
Further reading #
Here I focus on the high-level concept. If you want to read more about the technical workings, checkout this and this post.
Additionally, it turns out that git supports multiple working trees in one git repository. See the git-worktree. Interesting, I haven't used it yet.
Side note on complexity #
I now try to see everything through the eyes of Rich Hickey's Simple Made Easy & to spot complexity. The dotfiles use case is, perhaps, more of a theoretical exercise, but I find it valuable nevertheless. By doing thought experiments like this, I aim to solidify my understanding of complexity.
So, in this case, it seems that the symlinking approach complects two things: the dotfiles (the .gitconfig, the .zshrc) with the dotfile management (symlinks). These are two different concepts, intertwined in one repository. With a bare repository, we remove the complexity: the dotfiles are taken care of by the working tree, while dotfiles management is taken care of by git.
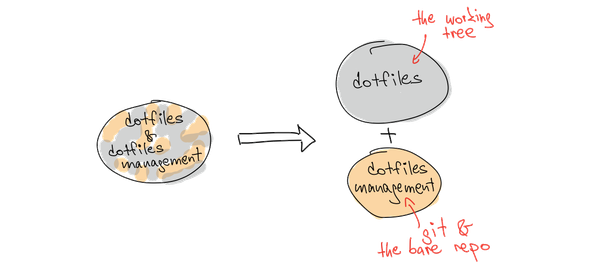
Another form of complexity is the imperative code for symlinking: first symlink that, then symlink that. At least that's how I had it coded. Since imperative programming complects how with what, it's complex. With a bare repository, we remove this form of complexity: the dotfiles become declarative; it's only the what.
There is one tradeoff, though. We introduce complexity in the form of inconsistent interaction with git. For dotfiles, we use an alias, such as gitdf; while for all other repos, we use git. For me, this complexity is negligible compared to the benefit of simplifying the symlinking process.
- ← Previous post: Adding domain knowledge to code comments
- → Next post: Connecting to AWS API Gateway with HTTP
This blog is written by Marcel Krcah, an independent consultant for product-oriented software engineering. If you like what you read, sign up for my newsletter